In this video, we will go over hashSets and hashes that are used with hashSets,
as well as hashing in general in the world. We will also refresh our memory on Tables(hashTables),
and add some more on that knowledge.
The code for this video and it's script/documentation styled with nimib,
is in the link in the description as a form of written tutorial.
Tables refresh
First of, we have already used a bit of hashing in my Tables video without even knowing it.
The tables module uses variants of an efficient hashTable(dictionaries in other programming languages).
Here is an example:
import std/tables
#The first key: value element that you use, will determine the data type for the Table#"Germany": "Berlin" -> string, stringvar countryCapitals = {"Germany": "Berlin", "Slovenia": "Ljubljana"}.toOrderedTable
echo countryCapitals
Don't forget to style/indent such Tables by commas like above.
It's a good practice to separate long lines of code by commas,
since it makes it much cleaner and easier to read.
Now, if we were to try to output each of the keys of the Table oldKobold and geomancerKobold with a for loop,
it wouldn't work, since the implicitly called items iterator,
does not exist for objects inside a Table.
The following code will not compile:
for kobold in koboldTable: #ERROR: implicitly called "items" iterator does not exist for Kobold object inside a Tableecho kobold
Now this can be solved in 2 ways. The first way is kinda messy,
and it involves using some boilerplate code to overload the items iterator,
as well as the hash proc from the hashes module,
which is used to hash the value into a more performant value.
This messy way, as well as a lot of details on what Hashing is, etc, later.
Let's solve this problem with the clean and easy solution,
of using the keys iterator specifically made for Tables.
Now, this code only outputs the actual keys of our table.
In order to get the values associated with those keys,
we must insert those keys back into our table with the index access [].
for kobold in koboldTable.keys:
echo kobold, " -> ", koboldTable[kobold]
There is also the values iterator amongst others for Tables.
This iterator will go trough all of the values of a Table,
just like how the keys iterator went trough all of the keys.
With this iterator, we then don't have to insert the key back into our Table to get the value,
when iterating over the entire Table like this:
for kobold in koboldTable.values:
echo kobold
fighter
mage
I believe i have never shown that you can also use multiple variables for capturing data in a for loop,
so let's do that with the pairs iterator:
for key, value in koboldTable.pairs:
echo"key: ", key, " -> value: ", value
The pairs iterator can also be used for when you want to capture the index,
when iterating over the elements of a container, like so:
for pos, ele in"Hello World!".pairs:
echo pos, " ", ele
0 H
1 e
2 l
3 l
4 o
5
6 W
7 o
8 r
9 l
10 d
11 !
What is hashing ?
Hashing is the process of transforming any given key or string,
into a usually another shorter and more efficient value,
by the use of a one way mathematical hashing algorithm/function.
One way algorithms are used, because Hashes are also used for encrypting data,
and a 2 way algorithm would fail that.
The most popular use for hashing, is the usage of hash tables. A hash table stores key and value pairs,
in a list that is accessible trough it's index. Because key and value pairs are unlimited,
the hash function will map the keys to the table size.
A hash value then becomes the index for a specific element.
Hashing is used in data indexing and retrieval, digital signatures, cybersecurity and cryptography.
They are also used on some websites, especially those dedicated to Linux OSs and programs,
to check your checksum(Secure Hash Algorithm/SHA, Message-Digest functions/MD),
against the one on their website, to ensure it is exactly the same,
without any tampering by a malicious person.
There are several modules in nim for dealing with hash function algorithms:
nimble install checksum before use of the Sha and MD5 modules
Sha1(old, used for legacy purposes)
Sha2(newer, but still insufficient for data security)
Sha3(newest, use this one)
MD5
Base64(for encoding and decoding data)
The usage of hashing in data structure, is used for the reasons of speed.
That speed is due to the fact that value is much smaller once hashed,
and also because hashed keys are mapped to the size of the Table,
which serves as an index to quickly find the desired data,
without the use of loops, which can take much longer to find the data.
There is a phenomenon called collision, which is when 2x or more hashes manage to generate an identical hash.
Different hash functions have different margin of collisions.
To address this, there are methods like:
Double hashing
Linear probing
Quadratic probing
Separate chaining(making every hash table cell point to linked lists of records with identical hash function values)
In cybersecurity, they can go a step further with the term Salting.
Which is adding random data into the hash function. It helps with attackers from accessing non-unique passwords,
by the use of rainbow tables(reverse engineered data)
Hashing in Nim
You can hash just about any data type in Nim. There is no list of what you can, but mostly everything.
You can easily hash your own data types, but first you must use a bit of skeleton/boilerplate code to do so.
The following 2 examples are taken from the hashes module page, that are required for your own data types.
Both of the examples are slightly renamed, with the first no longer overloading the items iterator,
from the implicitly imported system module, in order to avoid the items iterator,
from being used implicitly for yielding hashed values.
Remember, the items iterator is the one called by default implicitly(invisibly) in a for loop,
when not specifying the iterator.
Here is a quick reminder example:
for c in"Hello": #Nim's VS Code Extension will tell you the iterator used hereecho c
H
e
l
l
o
The above is the same as the following:
for c in"Hello".items:
echo c
H
e
l
l
o
Example 1 boilerplate code without using the implicitly called by default items iterator:
import std/hashes
typeCustomObject = object
foo: int
bar: stringiterator hashedFields(x: CustomObject): Hash =
yield hash(x.foo)
yield hash(x.bar)
proc hash(x: CustomObject): Hash =
## Computes a Hash from `x`.var h: Hash = 0# Iterate over parts of `x`.for xAtom in x.hashedFields:
# Mix the atom with the partial hash.
h = h !& xAtom
# Finish the hash.result = !$h
Sample code using the above example 1 boilerplate code which will output each field hashed separately:
var customObject = CustomObject(foo: 10, bar: "Hello")
for field in customObject.hashedFields: #Must use our "hashedFields" iterator -> otherwise errorecho field
-6375197177782184730
316307400
If your custom types contain fields for which there already is a hash proc,
you can simply hash together the hash values of the individual fields,
no need for the overload of the items iterator:
Example 2 without using an iterator(meaning you will have to hash explicitly):
typeCustomObject2 = object
foo: int
bar: stringproc hash(x: CustomObject2): Hash =
## Computes a Hash from `x`.var h: Hash = 0
h = h !& hash(x.foo)
h = h !& hash(x.bar) # "!&" Mixes a hash value "h" with "val" to produce a new hash value(only for custom types)result = !$h # "!$" Finishes the computation of the hash value(only for custom types)
Sample code using the example 2 boilerplate code(no iterator) which will output the entire object hashed:
var customObject2 = CustomObject2(foo: 20, bar: "World!")
echo customObject2.hash #No loop here, since it's not defined
-7400502187742009486
As you have seen from the outputs of the 2x examples of boilerplate code,
the very random looking data is the hashed value.
Hashing ref objects
Note: If the type has == operator, the following must hold:
If two values compare equal, their hashes must also be equal.
First of, i am going to show you what happens if you try to use a ref object,
for the key of a Table:
The following code will error, initTable[keyType, valueType]() does not work with ref objects.
It crashes immediately on any attempt of setting a ref object's fields(not the case for normal objects),
with the error message of SIGSEGV: Illegal storage access. (Attempt to read from nil?):
Slight change from earlier, ref objects and other ref containers,
require dereferencing via [].
Even though it appears that we don't need any boilerplate code to make it work,
again hashed values are much more performant than their non hashed counterparts.
This is especially true for objects, which are often quite numerous in fields,
fields which can contain other containers and other objects(structures).
Quick reminder:echo and the implicitly called items iterator, do not work with objects as keys inside Tables.
Also, do not overload the implicitly called by default items iterator.
Now let's hash our ref object of RefKobold.
First let's bring the above boilerplate code and modify it to RefKobold1(example 1),
as arguments of the custom hashedFields iterator and the hash proc overload.
import std/tables
import std/hashes
typeRefKobold1 = refobject
name: string
age: intiterator hashedFields(x: RefKobold1): Hash =
yield hash(x.name)
yield hash(x.age)
proc hash(x: RefKobold1): Hash =
## Computes a Hash from `x`.var h: Hash = 0# Iterate over parts of `x`.for xAtom in x.hashedFields:
# Mix the atom with the partial hash.
h = h !& xAtom
# Finish the hash.result = !$h
var
refOldKobold1 = RefKobold1(name: "Goldtooth", age: 31)
refGeomancerKobold1 = RefKobold1(name: "Rocktooth", age: 20)
refKoboldTable1 = {refOldKobold1: "fighter", refGeomancerKobold1: "mage"}.toOrderedTable
for key, value in refKoboldTable1:
echo""for field in key.hashedFields:
echo field
The following snippet of the code above is changed from example 1's from earlier to this,
because the earlier version only looped trough the object's fields inside a variable, not a Table like here:
for key, value in refKoboldTable1:
echo""for field in key.hashedFields:
echo field
Example 2 boilerplate code:
import std/tables
import std/hashes
typeRefKobold2 = refobject
name: string
age: intproc hash(x: RefKobold2): Hash =
## Computes a Hash from `x`.var h: Hash = 0
h = h !& hash(x.name)
h = h !& hash(x.age)
result = !$h
var
refOldKobold2 = RefKobold2(name: "Goldtooth", age: 31).hash # <-
refGeomancerKobold2 = RefKobold2(name: "Rocktooth", age: 20).hash # <-
refKoboldTable2 = {refOldKobold2: "fighter", refGeomancerKobold2: "mage"}.toOrderedTable
for key, value in refKoboldTable2.pairs:
echo key, " ", value
echo"Or just reinserting the key: ", key, " to get the value -> ", refKoboldTable2[key]
echo""
8548044415117994811 fighter
Or just reinserting the key: 8548044415117994811 to get the value -> fighter
-4179016716304925836 mage
Or just reinserting the key: -4179016716304925836 to get the value -> mage
All variants of Tables and some use cases
In this video, i have introduced you to the OrderedTable besides the normal unorded one from the Tables video.
There is also the CountTable for mapping from a key to it's number of occurrences.
And lastly, there a Ref/Reference versions of each, with Ref affixed/appended at the end like so:
TableRef( {}.newTable)
OrderedTableRef( {}.newOrderedTable)
CountTableRef( {}.newCountTable)
In case it wasn't clear on when to use Tables(hashTables) in Nim, here are a few examples/use cases:
Whenever you have 2 pieces of data that you want linked together(e.g. your phone contacts -> name : number)
Games/music listing on your computer(name of the game/music as key : value as location)
When generating JSON(lightweight data-interchange format), before it gets stringified, it's represented as a Table(dictionary)
Nested Tables(example 2 below)
Now let's make a new hashTable and hash one of it's keys,
and then reinsert the hashed key from the output back into itself:
Now lastly, i will show you a very useful proc for Tables called mgetOrPut.
mgetOrPut retrieves the value of a specified key,
or inserts/puts a (key,value) pair into the Table if that (key,value) pair is not present,
and then returns back the value of that key in a modifiable state( proc modifiable(a: var int) = ):
Now that modifiable state of the value, can easily be accidentally used to create a copy of the value,
instead of modifying it. This is the case when trying to use this mgetOrPut() proc with sequences and strings,
which are value types by design, meaning that they cannot be copied into a different variable,
and then use that variable to modify the value of a given key from the Table.
(This is mostly for people coming from other programming languages where sequences and strings are passed by reference)
(Note: if you see procs starting with m, as in mThenSomeProcName, it means it's modifiable e.g. mitems)
Here is an example of what not to do:
var declaredTable = newTable[int, seq[int]]() #No declaration with ":" for Tablesvar copiedTable = declaredTable.mgetOrPut(10, @[10])
#In other languages, this would add to key 10, 20 into @[10] -> 10: @[10, 20], not in Nim
copiedTable.add 20echo declaredTable
echo copiedTable
{10: @[10]}
@[10, 20]
Since the value returned by mgetOrPut proc is modifiable, you can do the following:
Now let's make the simplest hashSet data type a normal Set cannot use, String.
We cannot declare an empty hashSet, it can only be initialized.
So this example is just for show, since every hashSet is always initialized
in this same way by default anyways.
We are going to need the sets module for all hashSets.
import std/sets
var emptyHashSet = initHashSet[string]()
echo emptyHashSet
{}
Now the initialization version:
var hashedString = ["Hello, World!"].toHashSet
echo hashedString
{"Hello, World!"}
Now remember that the order of the elements is unordered, not the value of an element.
Now let's have a look on how hashSets and hashTables look like in procs:
proc paramHashSet(data: HashSet): HashSet = # data: initHashSet[string]() does NOT work
data
proc paramHashTable(data: Table): Table = #same for hashTables
data
proc initParamHashTable(data = {1: "one", 2: "two"}.toTable) =
echo data #We have to use this "data", the compiler will not let us return it with the "result" variable, it must be used right hereecho paramHashSet([3.14].toHashSet)
echo paramHashTable({1: "one"}.toTable)
initParamHashTable()
{3.14}
{1: "one"}
{2: "two", 1: "one"}
There is an additional operation you can do with hashSets that you cannot do with normal Sets, which is symmetricDifference(s1, s2).
-+- is the alias for that proc. This proc gives you only the elements that are not present in both sets at the same time.
E.g. if setA['a', 'b'] -+- setB['b', 'c'] = ['a', 'c'] because 'a' is only in one of them, and the same goes for 'c'.
'b' is in both of them so it gets excluded from this list.
let setSD1 = [("key1", 10), ("key2", 20)].toHashSet #Anonymous tuple - must be inside [], and tuples require (,) -> [()]let setSD2 = [("key2", 20), ("key3", 30)].toHashSet
echo setSD1
echo setSD2
echo""echo setSD1 -+- setSD2
There is also disjoint(s1, s2: bool) returns true if the sets s1 and s2 have no items in common,
let setD1 = [9223372036854775807, -9223372036854775807, 1, 2].toHashSet #9,223,372,036,854,775,807 or -/negative of that value is the max value of int64let setD2 = [2147483648, -2147483648, 1, 2].toHashSet #2,147,483,647 or -/negative of that value, is the max value of int32, had to add +1 and -1 at the end to make them int64, otherwise disjoint won't workecho setD1
echo setD2
echo""echo disjoint(setD1, setD2)
missingOrExcl(s, key) Excludes a key and tells you if the key was already missing from s. (no proc for missingOrIncl)
var setMOE = [1, 2, 3, 4, 5].toOrderedSet #So we can see the content of the set easierecho setMOE
if setMOE.missingOrExcl(1):
echo1, " true"else: echo"false"if setMOE.missingOrExcl(1):
echo1, " true"else: echo"false"echo setMOE
{1, 2, 3, 4, 5}
false
1 true
{2, 3, 4, 5}
containsOrIncl(s, key) Includes a key in the set s and tells if key was already in s.
Inverse of missingOrExcl(s, key)
var setCOI = [1, 2, 3, 4, 5].toOrderedSet #So we can see the content of the set easierecho setCOI
blockCOI:
if setCOI.containsOrIncl(6):
echo"6 was already in setCOI"else:
echo"6 is not is setCOI, adding"if setCOI.containsOrIncl(6):
echo"6 was already in setCOI"else:
echo"6 is not is setCOI, adding"
{1, 2, 3, 4, 5}
6 is not is setCOI, adding
6 was already in setCOI
map(data, op) Returns a new set after applying op -> proc(anonymous proc) on each of the elements of data set.
Here is a simple example from the Sets module that demonstrates the map proc very well:
let#using "let" since we wont be changing it with "b"
a = toHashSet([1, 2, 3])
b = a.map(proc (x: int): string = $x)
echo a
echo b
{3, 2, 1}
{"1", "2", "3"}
And here is my example at this proc:
let setM = ["lowercase", "UPPERCASE", "l", "U"].toHashSet #using "let" since we wont be changing itlet setNewL = setM.map(proc (elem: string): string =
for c in elem:
if c.isLowerAscii: #== true needless verbosityresult = elem)
let setNewU = setM.map(proc (elem: string): string =
for c in elem:
if c.isLowerAscii != true:
result = elem)
echo setNewL
echo setNewU
{"", "l", "lowercase"}
{"U", "", "UPPERCASE"}
The default return value of a proc returning string is "" empty string,
that is why there are 2x "" empty string elements in the output.
clear(s) Clears the hashSet back to an empty state, without shrinking any of the existing storage.
var someSizedSet = ["1", "2", "3", "4", "5"].toHashSet
var copiedSet = someSizedSet
echo"someSizedSet: ", someSizedSet, " of size: ", someSizedSet.sizeof, " bytes"echo"copiedSet: ", copiedSet, " of size: ", someSizedSet.sizeof, " bytes"
copiedSet.clear
echo""echo"someSizedSet: ", someSizedSet, " of size: ", someSizedSet.sizeof, " bytes"echo"copiedSet: ", copiedSet, " of size: ", someSizedSet.sizeof, " bytes"
someSizedSet: {"1", "3", "5", "2", "4"} of size: 24 bytes
copiedSet: {"1", "3", "5", "2", "4"} of size: 24 bytes
someSizedSet: {"1", "3", "5", "2", "4"} of size: 24 bytes
copiedSet: {} of size: 24 bytes
As you can see, the size remained at 24 bytes.
pop(s) Removes and returns an element from the set s.
You cannot specify which element to pop.
Here is some sample code that shows how it works(not the use case):
var myHashSet = ["a", "b", "c"].toHashSet
echo myHashSet.pop #You can't specify what element to popecho myHashSet.pop
echo myHashSet.pop
if myHashSet.len != 0:
echo myHashSet.pop
else:
echo"myHashSet is empty"
a
b
c
myHashSet is empty
There is a use case for the pop proc. For example if you have a pool of jobs to be done in no particular order.
Let's say that on weekends you clean your room, do your laundry, change the sheets, etc. That job only requires to be done once.
So you would use a doTheJob()/processJob() proc that would pop a job from your pool of jobs and execute it.
Once all the jobs are done, you can put the exact same ones back in when weekend comes, or some relatives are coming to visit.
Here is an example:
proc executeJob(job: string) =
echo job, " finished"var jobs = ["laundry", "sheets", "cleaning"].toHashSet
while jobs.len != 0:
let job = jobs.pop
job.executeJob
And lastly [] - Which returns the element that is actually stored in s which has the same value as key,
or raises the KeyError exception. This is useful when one overloaded the hash proc,
and the == operator, but still needs reference semantics for sharing.
One of the hashSet uses cases is very similar to the last use case example of the previous video of normal Sets.
The example being, splitting a string based on character elements as separators.
With hashSets, we can go a step further. We can use whole words as separators.
So let's use the split() proc we made in the last tutorial and update it for string hashSets.
We are also going to add another argument of type bool, to tell the proc if we are working with set[char],
or hashSet[string]. Currently the compiler cannot infer which to use,
since the second argument of seps is not an argument we can give, since it is already initialized.
Original version:
import std/strutils
proc split(s: string; seps: set[char] = {' ', '!', '?'}): string =
var splitString = s
var c: intfor sep in seps:
c = splitString.find(sep)
splitString.delete(c, c)
result = splitString
var myString = "Hello , World !?"echo myString
echo myString.split
Hello , World !?
Hello, World
Modified version:
import std/strutils
proc split(s: string; useNormalSet: bool): string =
if useNormalSet:
var seps: set[char] = {' ', '!', '?'}
var splitString = s
var c: intfor sep in seps:
c = splitString.find(sep)
splitString.delete(c, c)
result = splitString
else:
var seps = ["var", "let", "const"].toHashSet
var splitString = s
var c: intfor sep in seps:
c = splitString.find(sep)
if (c + sep.len) < splitString.len:
splitString.delete(c, c+sep.len)
result = splitString
echo myString.split(true)
echo"I have a var, a const, and a let me in pony".split(false) #43 length
Hello, World
I have a a and a me in pony
Quick re-explanation of hashing
In case i did not explain or convey this information well ->
Hashing a value with the hash proc(lower case "h"), returns a value of type Hash (uppercase "H"),
which allows for containers such as arrays, sequences, sets(hashSets), etc,
which only allow for a single data type to be used,
to instead store just about any data type you want.
Obviously this also works for variables and structures such as objects, tuples, etc.
Hash values must be available for any type that you want to use as a key in a so called Table data structure.
And also again, for hashing of usually complex and large structures such as objects,
and obviously Tables(implemented in such a way) for the reasons of speed.
Tables are also often called dictionaries or lookup tables.
Outro - Afterwords
Okay, that's it for this video, thanks for watching like, share and subscribe,
aswell as click the bell icon if you liked it and want more,
you can also follow me on twitter of the same name, and support me on Patreon.
If you had any problems with any part of the video,
let me know in the comment section,
the code of this video, script and documentation, are in the link in the description,
as a form of offline tutorial.
Thanks to my past and current Patrons
Past Patrons
Goose_Egg: From April 4th 2021 to May 10th 2022
Davide Galilei(1x month)
Current Patrons
jaap groot (from October 2023)
Dimitri Lesnoff (from October 2023)
Compiler Information
Version used: E.G. 2.0.2
Compiler settings used: none, ORC is now the default memory management option
#Do NOT use {} inside nbText: hlMdF""" """ fields, sometimes it will error, not always#When using - to make a line a list item, you cannot have ANY one of the lines be an empty line#Use spaces by a factor of 2x for indentation in levels# *text* italic# **text** for bold instead of <b></b># ***text*** italic bold#Link 1 - <a href = "link"></a>#Link 2 - [name](link)#Link 3 `name <link>`_ -> without a name works too#nbCodeSkip -> skips the output/echo calls from the file, everything else remains the same#nbCodeInBlock -> opens up a new scope like the "block" statement, useful for when you don't want to use different variable names etc#https://pietroppeter.github.io/nimib/allblocks.htmlimport nimib, std/strutils #You can use nimib's custom styling or HTML & CSS
nbInit()
nb.darkMode()
#nbShow() #This will auto open this file in the browser, but it does not check if it is already open#so it keeps bloody opening one after another, i just want a way to update changes quickly# customize source highlighting:
nb.context["highlight"] = """
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.5.0/styles/default.min.css">
<script src="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.5.0/highlight.min.js"></script>
<script>hljs.initHighlightingOnLoad();</script>"""# a custom text block that shows markdown sourcetemplate nbTextWithSource*(body: untyped) =
newNbBlock("nbTextWithSource", false, nb, nb.blk, body):
nb.blk.output = body
nb.blk.context["code"] = body
nb.renderPlans["nbTextWithSource"] = @["mdOutputToHtml"]
nb.partials["nbTextWithSource"] = """{{&outputToHtml}}
<pre><code class=\"language-markdown\">{{code}}</code></pre>"""#Overriding nimib's nbCode -> with a version that has horizontal scroll for overflowing outputimport nimib / [capture]
template nbCode(body: untyped) =
newNbCodeBlock("nbCode", body): #Writes to stdout `lineNumb typeOfNBblock: a bit of first line
captureStdout(nb.blk.output):
body
nb.partials["nbCode"] = """
{{>nbCodeSource}}
<pre><code class=\"language-markdown\" style = "color:white;background-color: rgba(255, 255, 255, 0);font-size: 12px;">{{>nbCodeOutput}}</code></pre>
"""
nb.renderPlans["nbCode"] = @["highlightCode"] # default partial automatically escapes output (code is escaped when highlighting)# how to add a ToCvar
nbToc: NbBlocktemplate addToc =
newNbBlock("nbText", false, nb, nbToc, ""):
nbToc.output = "## Table of Contents:\n\n"template nbSection(name:string) =
let anchorName = name.toLower.replace(" ", "-")
nbText "<a name = \"" & anchorName & "\"></a>\n# " & name & "\n\n---"# see below, but any number works for a numbered list
nbToc.output.add "1. <a href=\"#" & anchorName & "\">" & name & "</a>\n"#If you get an error from the above line, addToc must be ran before any nbSection template nbSubSection(name:string) =
index.subsection.inc
let anchorName = name.toLower.replace(" ", "-")
nbText "<a name = \"" & anchorName & "\"></a>\n## " & " " & $index.section & "." & $index.subsection & ". " & name & "\n\n---"# is inline HTML for a single white space(nothing in markdown)# see below, but any number works for a numbered list
nbToc.output.add " - " & $index.section & r"\." & $index.subsection & r"\. " & "<a href=\"#" & anchorName & "\">" & name & "</a>\n"#If you get an error from the above line, addToc must be ran before any nbSection template nbUoSection(name: string) =
nbText "\n# " & name & "\n\n---"template nbUoSubSection(name: string) =
nbText "\n## " & name & "\n\n---"#Updating the same file is shown instantly once deployed via Github Page on PC. #Mobile takes either a random amount of time, or NOT at all!template addButtonBackToTop() =
nbRawHtml: hlHtml"""
<meta name = "viewport" content = "width = device-width, initial-scale = 1">
<style>
body {} <!-- This is a comment, this needs to be here body {} -->
#toTop {
display: none;
position: fixed;
bottom: 20px;
right: 30px;
z-index: 99;
font-size: 18px;
border: none;
outline: none;
background-color: #1A222D;
color: white;
cursor: pointer;
padding: 15px;
border-radius: 4px;
}
#toTop:hover {background-color: #555;}
#toTopMobile {
display: none;
position: fixed;
bottom: -5px;
right: -5px;
z-index: 99;
font-size: 18px;
border: none;
outline: none;
background-color: #1A222D;
opacity: .2;
color: white;
cursor: pointer;
padding: 15px;
border-radius: 4px;
}
#toTopMobile:hover {background-color: #555;}
</style>
<body>
<button onclick = "topFunction()" id = "toTop" title = "Go to top">Top</button>
<button onclick = "topFunction()" id = "toTopMobile" title = "Go to top">Top</button>
<script>
// Get the button
let myButton = document.getElementById("toTop");
let myButtonMobile = document.getElementById("toTopMobile");
var currentButton = myButton
var hasTouchScreen = false;
//var contentBody = document.getElementsByTagName("body"); //gives a query object
//myButton.style.color = "red"; //This works
//myButton.textContent = contentBody; //This also works .innerHTML, .innerText
//document.body.scrollTop > 20 || document.documentElement.scrollTop > 20
//Above could be used to position the button relativly ?
// Detecting if the device is a mobile device
if ("maxTouchPoints" in navigator)
{
hasTouchScreen = navigator.maxTouchPoints > 0;
}
else if ("msMaxTouchPoints" in navigator)
{
hasTouchScreen = navigator.msMaxTouchPoints > 0;
}
else
{
var mQ = window.matchMedia && matchMedia("(pointer:coarse)");
if (mQ && mQ.media === "(pointer:coarse)")
{
hasTouchScreen = !!mQ.matches;
}
else if ('orientation' in window)
{
hasTouchScreen = true; // deprecated, but good fallback
}
else
{
// Only as a last resort, fall back to user agent sniffing
var UA = navigator.userAgent;
hasTouchScreen = (
/\b(BlackBerry|webOS|iPhone|IEMobile)\b/i.test(UA) ||
/\b(Android|Windows Phone|iPad|iPod)\b/i.test(UA)
);
}
}
if (hasTouchScreen)
currentButton = myButtonMobile
// When the user scrolls down 20px from the top of the document, show the button
window.onscroll = function()
{
scrollFunction()
};
function scrollFunction()
{
if (document.body.scrollTop > 20 || document.documentElement.scrollTop > 20) {
currentButton.style.display = "block";
} else {currentButton.style.display = "none";}
}
// When the user clicks on the button, scroll to the top of the document
function topFunction() {
document.body.scrollTop = 0;
document.documentElement.scrollTop = 0;
}
</script>
"""#TABLE OF CONTENTS - MUST BE RUN BEFORE ANY nbSection !!!
addToc()
addButtonBackToTop()
#Use Live Preview Extension and set the Auto Refresh Preview set to "On changes to Saved Files"#And Server Keep Alive After Embedded Preview Close set to 0, #so that we no longer need the preview embedded window, we now have it in the browser!#Live SERVER Extension no longer works, even with the .html file kept open################START OF FILE#################Adding hlMd or hlMdf enables nimiboost's markdown highlight mode
nbText: hlMdF"""
## INTRO - GREETING
- TITLE: hashSets, more on hashTables and hashing
## INTRO - FOREWORDS
<b>(What is the purpose of this video ?)</b>
- In this video, we will go over hashSets and hashes that are used with hashSets,
as well as hashing in general in the world. We will also refresh our memory on Tables(hashTables),
and add some more on that knowledge.
The code for this video and it's script/documentation styled with nimib,
is in the link in the description as a form of written tutorial.
"""
nbSection "Tables refresh"
nbText: """
First of, we have already used a bit of hashing in my Tables video without even knowing it.
The `tables` module uses variants of an efficient hashTable(dictionaries in other programming languages).
Here is an example:
"""
nbCode:
import std/tables
#The first key: value element that you use, will determine the data type for the Table#"Germany": "Berlin" -> string, stringvar countryCapitals = {"Germany": "Berlin", "Slovenia": "Ljubljana"}.toOrderedTable
echo countryCapitals
nbText: """
And here is an example of a nested table:
"""
nbCode:
var countryCapitalsWithPostCode = {"Germany": {"Berlin": 10000}.toOrderedTable,
"Slovenia": {"Ljubljana": 1000}.toOrderedTable}.toOrderedTable
echo countryCapitalsWithPostCode
echo countryCapitalsWithPostCode["Germany"], " ", countryCapitalsWithPostCode["Germany"].typeof
nbText: """
Don't forget to style/indent such Tables by commas like above.
It's a good practice to separate long lines of code by commas,
since it makes it much cleaner and easier to read.
"""
nbText: """
Now let's try Tables with an object for it's `key`:
"""
nbCode:
typeKobold = object
name: string
age: intvar oldKobold = Kobold(name: "Goldtooth", age: 31)
var geomancerKobold = Kobold(name: "Rocktooth", age: 20)
var koboldTable = {oldKobold: "fighter", geomancerKobold: "mage"}.toOrderedTable
echo koboldTable
nbText: """
Now, if we were to try to output each of the keys of the Table `oldKobold` and `geomancerKobold` with a for loop,
it wouldn't work, since the implicitly called `items` iterator,
does not exist for objects inside a Table.
The following code will not compile:
"""
nbCodeSkip:
for kobold in koboldTable: #ERROR: implicitly called "items" iterator does not exist for Kobold object inside a Tableecho kobold
nbText: """
Now this can be solved in 2 ways. The first way is kinda messy,
and it involves using some boilerplate code to overload the `items` iterator,
as well as the `hash` proc from the `hashes` module,
which is used to `hash` the value into a more performant value.
This messy way, as well as a lot of details on what Hashing is, etc, later.
Let's solve this problem with the clean and easy solution,
of using the `keys` iterator specifically made for `Tables`.
"""
nbCode:
for kobold in koboldTable.keys:
echo kobold
nbText: """
Now, this code only outputs the actual `keys` of our table.
In order to get the `values` associated with those `keys`,
we must insert those `keys` back into our table with the index access `[]`.
"""
nbCode:
for kobold in koboldTable.keys:
echo kobold, " -> ", koboldTable[kobold]
nbText: """
There is also the `values` iterator amongst others for Tables.
This iterator will go trough all of the `values` of a Table,
just like how the `keys` iterator went trough all of the `keys`.
With this iterator, we then don't have to insert the key back into our Table to get the value,
when iterating over the entire Table like this:
"""
nbCode:
for kobold in koboldTable.values:
echo kobold
nbText: """
I believe i have never shown that you can also use multiple variables for capturing data in a for loop,
so let's do that with the `pairs` iterator:
"""
nbCode:
for key, value in koboldTable.pairs:
echo"key: ", key, " -> value: ", value
nbText: """
The `pairs` iterator can also be used for when you want to capture the index,
when iterating over the elements of a container, like so:
"""
nbCode:
for pos, ele in"Hello World!".pairs:
echo pos, " ", ele
nbSection "What is hashing ?"
nbText: hlMdF"""
- Hashing is the process of transforming any given key or string,
into a usually another shorter and more efficient value,
by the use of a one way mathematical hashing algorithm/function.
- One way algorithms are used, because Hashes are also used for encrypting data,
and a 2 way algorithm would fail that.
- The most popular use for hashing, is the usage of hash tables. A hash table stores key and value pairs,
in a list that is accessible trough it's index. Because key and value pairs are unlimited,
the hash function will map the keys to the table size.
A hash value then becomes the index for a specific element.
- Hashing is used in data indexing and retrieval, digital signatures, cybersecurity and cryptography.
They are also used on some websites, especially those dedicated to Linux OSs and programs,
to check your checksum(Secure Hash Algorithm/SHA, Message-Digest functions/MD),
against the one on their website, to ensure it is exactly the same,
without any tampering by a malicious person.
- There are several modules in nim for dealing with hash function algorithms:
- `nimble install checksum` before use of the `Sha` and `MD5` modules
- Sha1(old, used for legacy purposes)
- Sha2(newer, but still insufficient for data security)
- Sha3(newest, use this one)
- MD5
- Base64(for encoding and decoding data)
- The usage of hashing in data structure, is used for the reasons of speed.
That speed is due to the fact that value is much smaller once hashed,
and also because hashed keys are mapped to the size of the Table,
which serves as an index to quickly find the desired data,
without the use of loops, which can take much longer to find the data.
- There is a phenomenon called `collision`, which is when 2x or more hashes manage to generate an identical hash.
Different hash functions have different margin of collisions.
To address this, there are methods like:
- Double hashing
- Linear probing
- Quadratic probing
- Separate chaining(making every hash table cell point to linked lists of records with identical hash function values)
- In cybersecurity, they can go a step further with the term Salting.
Which is adding random data into the hash function. It helps with attackers from accessing non-unique passwords,
by the use of rainbow tables(reverse engineered data)
"""
nbSection "Hashing in Nim"
nbText: hlMdF"""
You can hash just about any data type in Nim. There is no list of what you can, but mostly everything.
You can easily hash your own data types, but first you must use a bit of skeleton/boilerplate code to do so.
The following `2 examples` are taken from the hashes module page, that are required for your own data types.
Both of the examples are slightly renamed, with the first no longer overloading the `items` iterator,
from the implicitly imported `system` module, in order to avoid the `items` iterator,
from being used implicitly for yielding hashed values.
Remember, the `items` iterator is the one called by default implicitly(invisibly) in a for loop,
when not specifying the iterator.
Here is a quick reminder example:
"""
nbCode:
for c in"Hello": #Nim's VS Code Extension will tell you the iterator used hereecho c
nbRawHtml: """<img src="images/vsCodeNimExtensionHelper.png" alt="VS Code Nim Extension Help/Details">"""
nbText: """
The above is the same as the following:
"""
nbCode:
for c in"Hello".items:
echo c
nbText: """
**Example 1** boilerplate code without using the implicitly called by default `items` iterator:
"""
nbCode:
import std/hashes
typeCustomObject = object
foo: int
bar: stringiterator hashedFields(x: CustomObject): Hash =
yield hash(x.foo)
yield hash(x.bar)
proc hash(x: CustomObject): Hash =
## Computes a Hash from `x`.var h: Hash = 0# Iterate over parts of `x`.for xAtom in x.hashedFields:
# Mix the atom with the partial hash.
h = h !& xAtom
# Finish the hash.result = !$h
nbText: """
Sample code using the above **example 1** boilerplate code which will output each field hashed separately:
"""
nbCode:
var customObject = CustomObject(foo: 10, bar: "Hello")
for field in customObject.hashedFields: #Must use our "hashedFields" iterator -> otherwise errorecho field
nbText: hlMdF"""
If your custom types contain fields for which there already is a `hash` proc,
you can simply hash together the hash values of the individual fields,
no need for the overload of the `items` iterator:
**Example 2** without using an iterator(meaning you will have to `hash` explicitly):
"""
nbCode:
typeCustomObject2 = object
foo: int
bar: stringproc hash(x: CustomObject2): Hash =
## Computes a Hash from `x`.var h: Hash = 0
h = h !& hash(x.foo)
h = h !& hash(x.bar) # "!&" Mixes a hash value "h" with "val" to produce a new hash value(only for custom types)result = !$h # "!$" Finishes the computation of the hash value(only for custom types)
nbText: """
Sample code using the **example 2** boilerplate code(no iterator) which will output the entire object hashed:
"""
nbcode:
var customObject2 = CustomObject2(foo: 20, bar: "World!")
echo customObject2.hash #No loop here, since it's not defined
nbText: hlMdF"""
As you have seen from the outputs of the 2x examples of boilerplate code,
the very random looking data is the hashed value.
"""
nbSection: "Hashing ref objects"
nbText: """
- **Note:** If the type has `==` operator, the following must hold:
If two values compare equal, their hashes must also be equal.
First of, i am going to show you what happens if you try to use a `ref object`,
for the `key` of a Table:
"""
nbCode:
import std/tables
import std/hashes
typeRefKobold = refobject
name: string
age: int
nbText: hlMd"""
The following code will error, `initTable[keyType, valueType]()` does not work with **ref objects**.
It crashes immediately on any attempt of setting a **ref object**'s **fields**(not the case for normal objects),
with the error message of **SIGSEGV: Illegal storage access. (Attempt to read from nil?)**:
"""
nbCodeSkip:
var
refKoboldTable = initTable[RefKobold, string]()
refOldKobold: RefKobold
refGeomancerKobold: RefKobold
refOldKobold.name = "Goldtooth"
nbText: hlMd"""
So let's do what we did so far without the use of `initTable[ keyType, valueType ]()`,
but with direct initialization `{}.toOrderedTable`:
"""
nbCode:
var
refOldKobold = RefKobold(name: "Goldtooth", age: 31)
refGeomancerKobold = RefKobold(name: "Rocktooth", age: 20)
refKoboldTable = {refOldKobold: "fighter", refGeomancerKobold: "mage"}.toOrderedTable
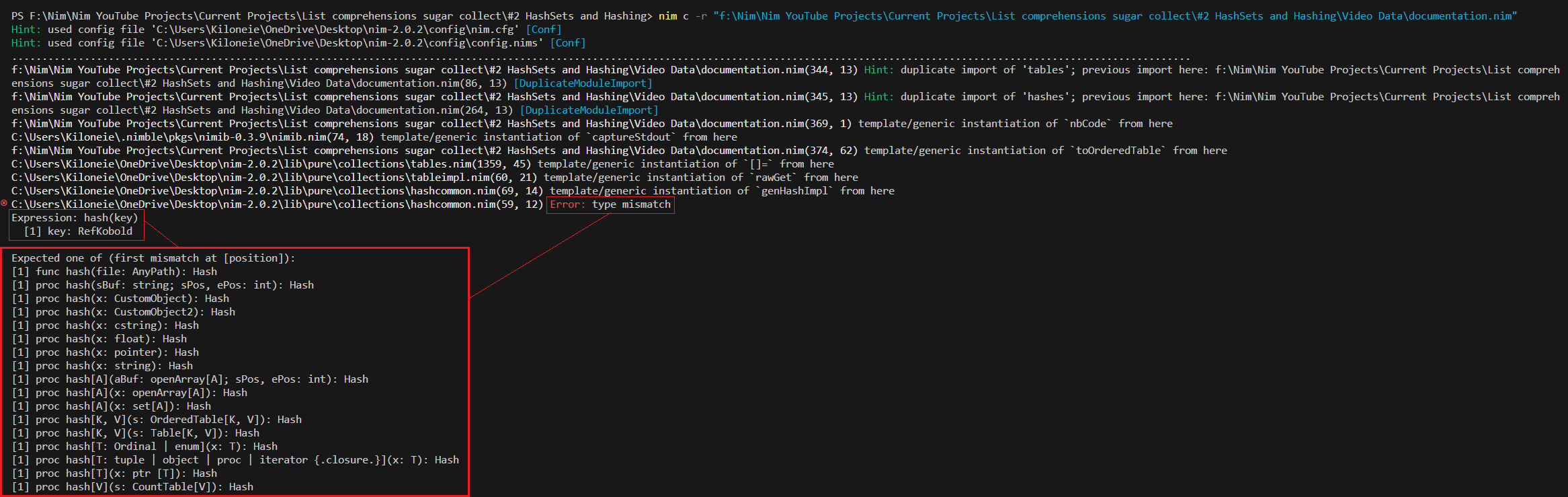
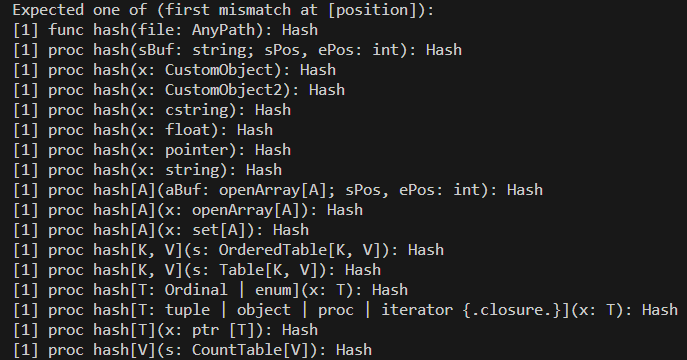
refOldKobold.name = "NewGoldTooth"#nbImage(url="images/CompilerErrorCropped.png", caption="Ref Object Compiler Error")#for some reason it's not showing...
nbRawHtml: """<img src="images/CompilerError.png" alt="Ref Object Compiler Error">"""
nbRawHtml: """<img src="images/CompilerErrorCropped.png" alt="Ref Object Compiler Error Cropped">"""
nbText: """
As you can see, we get an error.
This can be easily fixed by using the following compiler configuration parameter with a `config.nims` config file:
- `--d:nimPreviewHashRef`(1x "-" less when used in the terminal)
This configuration parameter allows for hashing of ref objects,
and will likely be used by default in future version of Nim.
Due note that we haven't actually `hashed` the key(RefKobold) yet.
Now that the above code works, let's quickly see if the `keys`, `values` and `pairs` iterators,
work with the `ref` version of our Kobold object:
"""
nbCode:
for key in refKoboldTable.keys: #Yesecho key[]
nbCode:
for v in refKoboldTable.values: #Yesecho v
nbCode:
for key, value in refKoboldTable.pairs: #Yesecho key[], " ", value
nbText: """
Slight change from earlier, `ref` objects and other `ref` containers,
require dereferencing via `[]`.
"""
nbText: """
Even though it appears that we don't need any boilerplate code to make it work,
again `hashed` values are much more performant than their non hashed counterparts.
This is especially true for `objects`, which are often quite numerous in fields,
fields which can contain other containers and other objects(structures).
**Quick reminder:** `echo` and the implicitly called `items` iterator, do not work with objects as keys inside Tables.
Also, do not overload the implicitly called by default `items` iterator.
"""
nbText: """
Now let's hash our `ref object` of RefKobold.
First let's bring the above boilerplate code and modify it to `RefKobold1`(example 1),
as arguments of the custom `hashedFields` iterator and the `hash` proc overload.
- iterator hashedFields(x: `Kobold`): Hash = -> iterator hashedFields(x: `RefKobold1`): Hash =
- proc hash(x: `Kobold`): Hash = -> proc hash(x: `RefKobold1`): Hash =
**Example 1 boilerplate code:**
"""
nbCode:
import std/tables
import std/hashes
typeRefKobold1 = refobject
name: string
age: intiterator hashedFields(x: RefKobold1): Hash =
yield hash(x.name)
yield hash(x.age)
proc hash(x: RefKobold1): Hash =
## Computes a Hash from `x`.var h: Hash = 0# Iterate over parts of `x`.for xAtom in x.hashedFields:
# Mix the atom with the partial hash.
h = h !& xAtom
# Finish the hash.result = !$h
var
refOldKobold1 = RefKobold1(name: "Goldtooth", age: 31)
refGeomancerKobold1 = RefKobold1(name: "Rocktooth", age: 20)
refKoboldTable1 = {refOldKobold1: "fighter", refGeomancerKobold1: "mage"}.toOrderedTable
for key, value in refKoboldTable1:
echo""for field in key.hashedFields:
echo field
nbText: """
The following snippet of the code above is changed from `example 1`'s from earlier to this,
because the earlier version only looped trough the `object`'s fields inside a variable, not a `Table` like here:
"""
nbCodeSkip:
for key, value in refKoboldTable1:
echo""for field in key.hashedFields:
echo field
nbText: """
**Example 2 boilerplate code:**
"""
nbCode:
import std/tables
import std/hashes
typeRefKobold2 = refobject
name: string
age: intproc hash(x: RefKobold2): Hash =
## Computes a Hash from `x`.var h: Hash = 0
h = h !& hash(x.name)
h = h !& hash(x.age)
result = !$h
var
refOldKobold2 = RefKobold2(name: "Goldtooth", age: 31).hash # <-
refGeomancerKobold2 = RefKobold2(name: "Rocktooth", age: 20).hash # <-
refKoboldTable2 = {refOldKobold2: "fighter", refGeomancerKobold2: "mage"}.toOrderedTable
for key, value in refKoboldTable2.pairs:
echo key, " ", value
echo"Or just reinserting the key: ", key, " to get the value -> ", refKoboldTable2[key]
echo""
nbSection: "All variants of Tables and some use cases"
nbText: hlMd"""
In this video, i have introduced you to the OrderedTable besides the normal unorded one from the Tables video.
There is also the CountTable for mapping from a key to it's number of occurrences.
And lastly, there a Ref/Reference versions of each, with `Ref` affixed/appended at the end like so:
- TableRef( {}.newTable)
- OrderedTableRef( {}.newOrderedTable)
- CountTableRef( {}.newCountTable)
In case it wasn't clear on when to use Tables(hashTables) in Nim, here are a few examples/use cases:
- Whenever you have 2 pieces of data that you want linked together(e.g. your phone contacts -> name : number)
- Games/music listing on your computer(name of the game/music as key : value as location)
- When generating JSON(lightweight data-interchange format), before it gets stringified, it's represented as a Table(dictionary)
- Nested Tables(example 2 below)
Now let's make a new hashTable and hash one of it's keys,
and then reinsert the hashed key from the output back into itself:
"""
nbCode:
import std/tables
var tData = {1.hash: "one", 2: "two"}.toTable
echo tData
echo tData[8641844181895329213]
echo tData[2]
nbText: hlMd"""
Here we go, it worked perfectly.
"""
nbText: hlMd"""
Now lastly, i will show you a very useful proc for Tables called `mgetOrPut`.
`mgetOrPut` retrieves the value of a specified key,
or inserts/puts a (key,value) pair into the Table if that (key,value) pair is not present,
and then returns back the value of that key in a modifiable state( `proc modifiable(a: var int) =` ):
"""
nbCode:
var stringIntTable = {"a": 1, "b": 4}.newTable
echo stringIntTable
echo stringIntTable.mgetOrPut("a", 10), " ", stringIntTable
echo stringIntTable.mgetOrPut("b", 10), " ", stringIntTable
echo stringIntTable.mgetOrPut("c", 10), " ", stringIntTable
echo stringIntTable
nbText: """
Now that modifiable state of the value, can easily be accidentally used to create a copy of the value,
instead of modifying it. This is the case when trying to use this `mgetOrPut() proc` with sequences and strings,
which are value types by design, meaning that they cannot be copied into a different variable,
and then use that variable to modify the value of a given key from the Table.
(This is mostly for people coming from other programming languages where sequences and strings are passed by reference)
(Note: if you see procs starting with `m`, as in `mThenSomeProcName`, it means it's modifiable e.g. `mitems`)
Here is an example of what not to do:
"""
nbCode:
var declaredTable = newTable[int, seq[int]]() #No declaration with ":" for Tablesvar copiedTable = declaredTable.mgetOrPut(10, @[10])
#In other languages, this would add to key 10, 20 into @[10] -> 10: @[10, 20], not in Nim
copiedTable.add 20echo declaredTable
echo copiedTable
nbText: """
Since the value returned by `mgetOrPut` proc is modifiable, you can do the following:
"""
nbCode:
declaredTable.mgetOrPut(10, @[10]).add 50echo declaredTable
nbSection: "hashSets"
nbText: hlMd"""
First of, hashSets are allocated on the heap.
Now let's make the simplest hashSet data type a normal Set cannot use, String.
We cannot declare an empty hashSet, it can only be initialized.
So this example is just for show, since every hashSet is always initialized
in this same way by default anyways.
We are going to need the `sets` module for all hashSets.
"""
nbCode:
import std/sets
var emptyHashSet = initHashSet[string]()
echo emptyHashSet
nbText: hlMd"""
Now the initialization version:
"""
nbCode:
var hashedString = ["Hello, World!"].toHashSet
echo hashedString
nbText: hlMd"""
Now remember that the order of the elements is unordered, not the value of an element.
Now let's have a look on how hashSets and hashTables look like in procs:
"""
nbCode:
proc paramHashSet(data: HashSet): HashSet = # data: initHashSet[string]() does NOT work
data
proc paramHashTable(data: Table): Table = #same for hashTables
data
proc initParamHashTable(data = {1: "one", 2: "two"}.toTable) =
echo data #We have to use this "data", the compiler will not let us return it with the "result" variable, it must be used right hereecho paramHashSet([3.14].toHashSet)
echo paramHashTable({1: "one"}.toTable)
initParamHashTable()
nbText: hlMd"""
There is an additional operation you can do with hashSets that you cannot do with normal Sets, which is `symmetricDifference(s1, s2)`.
`-+-` is the alias for that proc. This proc gives you only the elements that are not present in both sets at the same time.
E.g. `if setA['a', 'b'] -+- setB['b', 'c'] = ['a', 'c']` because `'a'` is only in one of them, and the same goes for `'c'`.
`'b'` is in both of them so it gets excluded from this list.
"""
nbCode:
let setSD1 = [("key1", 10), ("key2", 20)].toHashSet #Anonymous tuple - must be inside [], and tuples require (,) -> [()]let setSD2 = [("key2", 20), ("key3", 30)].toHashSet
echo setSD1
echo setSD2
echo""echo setSD1 -+- setSD2
nbText: hlMd"""
There is also `disjoint(s1, s2: bool)` returns true if the sets s1 and s2 have no items in common,
"""
nbCode:
let setD1 = [9223372036854775807, -9223372036854775807, 1, 2].toHashSet #9,223,372,036,854,775,807 or -/negative of that value is the max value of int64let setD2 = [2147483648, -2147483648, 1, 2].toHashSet #2,147,483,647 or -/negative of that value, is the max value of int32, had to add +1 and -1 at the end to make them int64, otherwise disjoint won't workecho setD1
echo setD2
echo""echo disjoint(setD1, setD2)
nbText: hlMd"""
`missingOrExcl(s, key)` Excludes a key and tells you if the key was already missing from `s`. (no proc for missingOrIncl)
"""
nbCode:
var setMOE = [1, 2, 3, 4, 5].toOrderedSet #So we can see the content of the set easierecho setMOE
if setMOE.missingOrExcl(1):
echo1, " true"else: echo"false"if setMOE.missingOrExcl(1):
echo1, " true"else: echo"false"echo setMOE
nbText: hlMd"""
`containsOrIncl(s, key)` Includes a key in the set `s` and tells if key was already in `s`.
Inverse of missingOrExcl(s, key)
"""
nbCode:
var setCOI = [1, 2, 3, 4, 5].toOrderedSet #So we can see the content of the set easierecho setCOI
blockCOI:
if setCOI.containsOrIncl(6):
echo"6 was already in setCOI"else:
echo"6 is not is setCOI, adding"if setCOI.containsOrIncl(6):
echo"6 was already in setCOI"else:
echo"6 is not is setCOI, adding"
nbText: hlMd"""
`map(data, op)` Returns a new set after applying `op` -> `proc(anonymous proc)` on each of the elements of `data` set.
Here is a simple example from the Sets module that demonstrates the `map` proc very well:
"""
nbCode:
let#using "let" since we wont be changing it with "b"
a = toHashSet([1, 2, 3])
b = a.map(proc (x: int): string = $x)
echo a
echo b
nbText: hlMd"""
And here is my example at this proc:
"""
nbCode:
let setM = ["lowercase", "UPPERCASE", "l", "U"].toHashSet #using "let" since we wont be changing itlet setNewL = setM.map(proc (elem: string): string =
for c in elem:
if c.isLowerAscii: #== true needless verbosityresult = elem)
let setNewU = setM.map(proc (elem: string): string =
for c in elem:
if c.isLowerAscii != true:
result = elem)
echo setNewL
echo setNewU
nbText: hlMd"""
The default return value of a proc returning string is `""` empty string,
that is why there are 2x `""` empty string elements in the output.
"""
nbText: hlMd"""
`clear(s)` Clears the hashSet back to an empty state, without shrinking any of the existing storage.
"""
nbCode:
var someSizedSet = ["1", "2", "3", "4", "5"].toHashSet
var copiedSet = someSizedSet
echo"someSizedSet: ", someSizedSet, " of size: ", someSizedSet.sizeof, " bytes"echo"copiedSet: ", copiedSet, " of size: ", someSizedSet.sizeof, " bytes"
copiedSet.clear
echo""echo"someSizedSet: ", someSizedSet, " of size: ", someSizedSet.sizeof, " bytes"echo"copiedSet: ", copiedSet, " of size: ", someSizedSet.sizeof, " bytes"
nbText: hlMd"""
As you can see, the size remained at 24 bytes.
"""
nbText: hlMd"""
`pop(s)` Removes and returns an element from the set `s`.
You cannot specify which element to pop.
Here is some sample code that shows how it works(not the use case):
"""
nbCode:
var myHashSet = ["a", "b", "c"].toHashSet
echo myHashSet.pop #You can't specify what element to popecho myHashSet.pop
echo myHashSet.pop
if myHashSet.len != 0:
echo myHashSet.pop
else:
echo"myHashSet is empty"
nbText: hlMd"""
**There is a use case for the `pop`** proc. For example if you have a pool of jobs to be done in no particular order.
Let's say that on weekends you clean your room, do your laundry, change the sheets, etc. That job only requires to be done once.
So you would use a doTheJob()/processJob() proc that would `pop` a job from your pool of jobs and execute it.
Once all the jobs are done, you can put the exact same ones back in when weekend comes, or some relatives are coming to visit.
Here is an example:
"""
nbCode:
proc executeJob(job: string) =
echo job, " finished"var jobs = ["laundry", "sheets", "cleaning"].toHashSet
while jobs.len != 0:
let job = jobs.pop
job.executeJob
nbText: hlMd"""
And lastly `[]` - Which returns the element that is actually stored in `s` which has the same value as `key`,
or raises the `KeyError` exception. This is useful when one overloaded the `hash` proc,
and the `==` operator, but still needs reference semantics for sharing.
"""
nbCode:
var setWithAKey = ["one", "two", "tree"].toHashSet
echo setWithAKey["one"], " ", setWithAKey["one"].type
nbSection: "hashSet use cases"
nbText: hlMd"""
One of the hashSet uses cases is very similar to the last use case example of the previous video of normal Sets.
The example being, splitting a string based on character elements as separators.
With hashSets, we can go a step further. We can use whole words as separators.
So let's use the `split()` proc we made in the last tutorial and update it for string hashSets.
We are also going to add another argument of type bool, to tell the proc if we are working with set[char],
or hashSet[string]. Currently the compiler cannot infer which to use,
since the second argument of `seps` is not an argument we can give, since it is already initialized.
"""
nbText: hlMd"""
**Original version:**
"""
nbCode: #Original versionimport std/strutils
proc split(s: string; seps: set[char] = {' ', '!', '?'}): string =
var splitString = s
var c: intfor sep in seps:
c = splitString.find(sep)
splitString.delete(c, c)
result = splitString
var myString = "Hello , World !?"echo myString
echo myString.split
nbText: hlMd"""
**Modified version:**
"""
nbCode: #Modified version for string hashSetsimport std/strutils
proc split(s: string; useNormalSet: bool): string =
if useNormalSet:
var seps: set[char] = {' ', '!', '?'}
var splitString = s
var c: intfor sep in seps:
c = splitString.find(sep)
splitString.delete(c, c)
result = splitString
else:
var seps = ["var", "let", "const"].toHashSet
var splitString = s
var c: intfor sep in seps:
c = splitString.find(sep)
if (c + sep.len) < splitString.len:
splitString.delete(c, c+sep.len)
result = splitString
echo myString.split(true)
echo"I have a var, a const, and a let me in pony".split(false) #43 length
nbSection: "Quick re-explanation of hashing"
nbText: """
In case i did not explain or convey this information well ->
Hashing a value with the `hash` proc(lower case "h"), returns a value of type `Hash` (uppercase "H"),
which allows for containers such as `arrays`, `sequences`, `sets(hashSets)`, etc,
which only allow for a single data type to be used,
to instead store just about `any` data type you want.
Obviously this also works for variables and structures such as objects, tuples, etc.
Hash values must be available for any type that you want to use as a `key` in a so called Table data structure.
And also again, for `hashing` of usually complex and large structures such as `objects`,
and obviously Tables(implemented in such a way) for the reasons of `speed`.
Tables are also often called dictionaries or `lookup` tables.
"""
nbUoSection "Outro - Afterwords"
nbText: """
Okay, that's it for this video, thanks for watching like, share and subscribe,
aswell as click the bell icon if you liked it and want more,
you can also follow me on twitter of the same name, and support me on Patreon.
If you had any problems with any part of the video,
let me know in the comment section,
the code of this video, script and documentation, are in the link in the description,
as a form of offline tutorial.
"""
nbUoSection "Thanks to my past and current Patrons"
nbUoSubSection "Past Patrons"
nbText: """
- Goose_Egg: From April 4th 2021 to May 10th 2022
- Davide Galilei(1x month)
"""
nbUoSubSection "Current Patrons"
nbText: """
- jaap groot (from October 2023)
- Dimitri Lesnoff (from October 2023)
"""
nbUoSubSection "Compiler Information"
nbText: """
- Version used: E.G. 2.0.2
- Compiler settings used: none, ORC is now the default memory management option
- Timestamps:
- 00:15 Start of video example
"""
nbUoSubSection "My and General Links"
nbText: """
- [Twitter](https://twitter.com/Kiloneie "My Twitter")
- [Patreon](https://www.patreon.com/Kiloneie?fan_landing=true "Patreon")
- [Visual Studio Code Shortcuts](https://code.visualstudio.com/shortcuts/keyboard-shortcuts-windows.pdf "Visual Studio Code Shortcuts")
"""
nbUoSubSection "Links to this video's subject"
nbText: """
- [Tables(hashTables)](https://nim-lang.org/docs/tables.html "Tables(hashTables)")
- [hashSets](https://nim-lang.org/docs/sets.html "hashSets")
- [Hashes](https://nim-lang.org/docs/hashes.html "Hashes")
"""
nbSave()